3. Pulsar2 工具链概述#
3.1. 简介#
Pulsar2 由 爱芯元智 自主研发 的 all-in-one 新一代神经网络编译器,
即 转换、 量化、 编译、 异构 四合一, 实现深度学习神经网络模型 快速、 高效 的部署需求.
针对新一代 AX6、AX88、M7、M5 系列芯片特性进行了深度定制优化, 充分发挥片上异构计算单元(CPU+NPU)算力, 提升神经网络模型的产品部署效率.
特别说明:
- 工具链文档中的提示说明
Note: 注释内容,对某些专业词做进一步解释说明
Hint: 提示内容,提醒用户确认相关信息
Attention: 注意内容,提醒用户对工具配置的相关注意事项
Warning: 告警内容,提醒用户注意工具链的正确使用方法。如果客户没有按Warning提示内容进行使用,有可能会出现错误结果。
工具链文档中的命令兼容车载芯片,例如
Pulsar2支持M76H工具链文档中的 示例命令、 示例输出 均基于
AX650进行展示具体芯片的算力配置,以芯片SPEC为准
Pulsar2 工具链核心功能是将 .onnx 模型编译成芯片能解析并运行的 .axmodel 模型.
部署流程
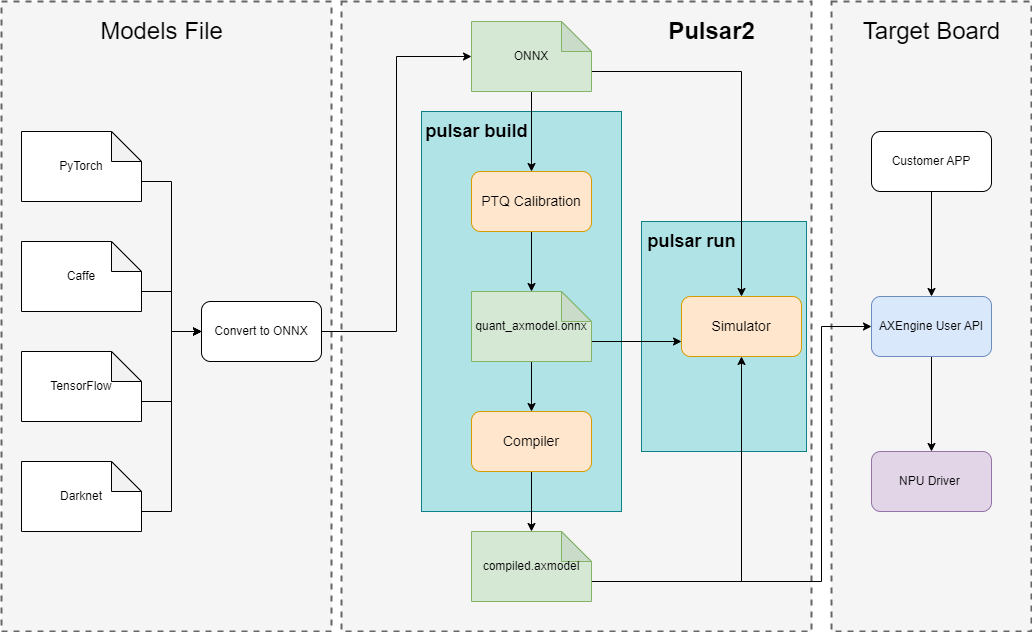
3.2. 后续章节内容引导#
Quick Start: 本章介绍开发环境准备,以及各芯片平台上的基本应用流程
模型转换进阶:本章为模型转换的进阶说明,即详细介绍如何利用
Pulsar2 Docker工具链将onnx模型转换为axmodel模型模型仿真进阶: 本章为模型仿真的进阶说明,即详细介绍如何使用
axmodel模型在x86平台上仿真运行并衡量推理结果与onnx推理结果之间的差异度(内部称之为对分)模型上板运行进阶: 本章为模型上板运行的进阶说明,即详细介绍如何上板运行
axmodel得到模型在爱芯SOC硬件上的推理结果配置文件说明: 本章对模型转换编译过程使用的配置文件进行详细说明
Caffe 转 ONNX 工具: Caffe AI 训练平台导出的模型不是NPU工具链支持的
onnx格式,需要一个工具把 Caffe 模型转换成onnx模型。本章介绍这个模型转换工具的使用方法。模型板上速度和精度测试工具: 本章为模型板上速度和精度测试工具的使用说明
QAT 4W8F: 本章为 QAT 4W8F 的简略使用说明
功能安全声明: 本章为 NPU 工具链功能安全符合性的声明
附录:文档附录部分包括算子支持列表、精度调优建议
备注
所谓 对分, 即对比工具链编译前后的同一个模型不同版本 (文件类型) 推理结果之间的误差。