6. 精度调优建议#
在部署过程中,不可避免的会出现一些精度损失。这篇文档用于指导用户进行精度损失的排查。
通常情况下,可以通过逐层精度对比表格来粗略判断模型转换过程中精度损失情况。 开启的方法如下:
{
...
"quant": {
"precision_analysis": true,
"precision_analysis_mode": "NPUBackend",
"precision_analysis_method": "EndToEnd"
},
...
}
这样在编译过程中会输出一个逐层的余弦相似度表格,如果模型最后的输出层 余弦相似度 > 98% ,此时可以粗判量化后的模型精度正常,可以上板验证精度。
如果以上指标未达到或者模型的实际上板精度误差较大,我们建议查看以下章节来进行精度调优。
6.1. 精度损失的原因#
造成精度损失的原因会有许多情况,大致上分为两类: 模型转换精度损失和部署精度损失 。
模型转换精度损失指在执行 Pulsar2 build 过程中从浮点量化到低比特和硬件实现差异带来的精度损失。
部署精度损失指训练侧代码转换到实际部署代码过程中由于预处理后处理不对齐带来的精度损失。
我们建议先排查部署流程中的精度损失,再排查模型转换精度损失。
6.2. 部署精度损失#
在部署过程中,前后处理未对齐通常是影响精度的重要原因。
6.2.1. 排除干扰项#
排查前后处理问题时,为了避免干扰,在配置文件中,应当将 input_processors 显示配置成与浮点模型一致。比如shape为 1x3x224x224 的输入,配置文件应当如下:
{
...
"input_processors": [
{
"tensor_name": "DEFAULT",
"tensor_format": "BGR",
"tensor_layout": "NCHW",
"src_format": "BGR",
"src_dtype": "FP32",
"src_layout": "NCHW",
"mean": [0,0,0],
"std": [1,1,1]
}
],
"output_processors": [
{
"tensor_name": "DEFAULT"
}
],
...
}
在编译完成后,可以使用 netron 查看编译完成的 compiled.axmodel 输入是否与浮点模型的类型和shape一致。例如:
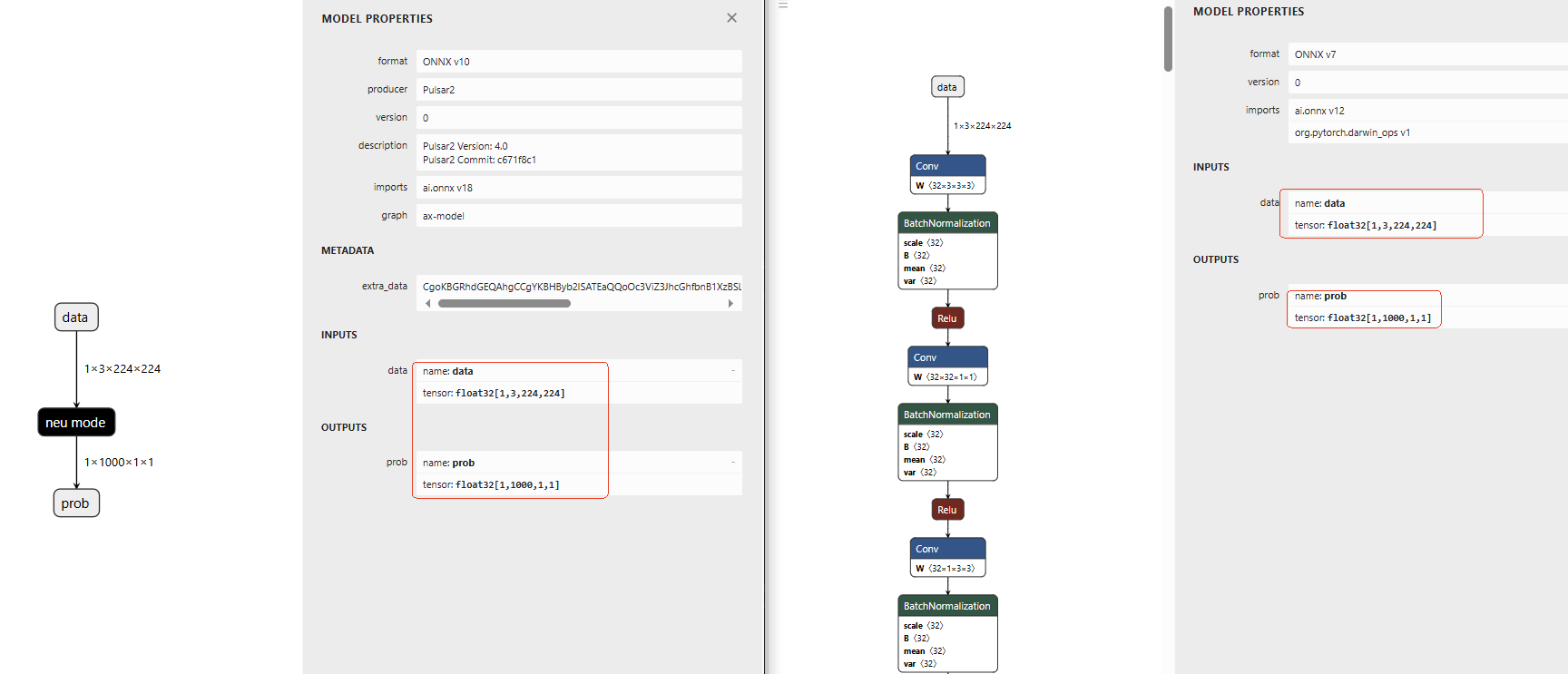
这样就能保证编译出来的模型中与浮点模型的输入输出类型一致。
6.2.2. 对齐前后处理#
按照如下流程对齐上板时的前后处理与训练阶段推理时的前后处理。
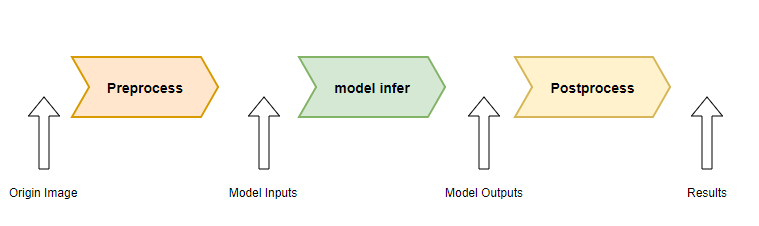
单个数据,使用训练时的Python推理代码将原始输入,预处理后的数据 ,模型输出,后处理后的数据 保存成bin文件;这里可以将结果进行可视化,以确保输出的正确性
板端测试预处理:读取上一步保存下来的原始数据,做为输入,得到板端预处理后的结果,与上一步保存的预处理后的数据进行比较,当两者误差在 0.0001 (1e-4) 以内时认为误差符合预期,即 (a - b) < 0.0001 。
板端测试后处理:读取第一步保存下来的模型输出,做为模型输出,并计算后处理, 得到板端后处理的结果,与第一步保存的后处理后的数据进行比较,当两者逐元素比较误差在 0.001 (1e-3) 以内时认为误差符合预期。 。
提示
在github上也提供了python实现的 pyaxengine ,接口与 onnxruntime 完全对齐,可以用于排除前后处理未对齐带来的精度损失。
6.3. 模型转换精度损失#
模型转换也会带来一定的精度损失,我们建议按照 基础问题排查 、量化精度调优的过程进行。
6.3.1. 基础问题排查#
在排查精度问题时,先确认下列选项,再进行精度调优:
mean/std 与训练时一致:如果量化使用的数据集使用的格式为
Image,请确保quant中的input_configs下的calibration_mean以及calibration_std与训练时一致。BGR与RGB格式:如果量化使用的数据集使用的格式为
Image,请确保input_processors中的tensor_layout与训练时一致。- 量化数据集是否正确:
校准图片与使用场景尽量相同
校准集数量是否场景足够丰富,应尽量覆盖所有类别
6.3.2. 量化精度调优#
通过更改量化策略来提升模型精度,目前可尝试的有 MSE Percentile MinMax ,对应 quant 字段中的 calibration_method 。
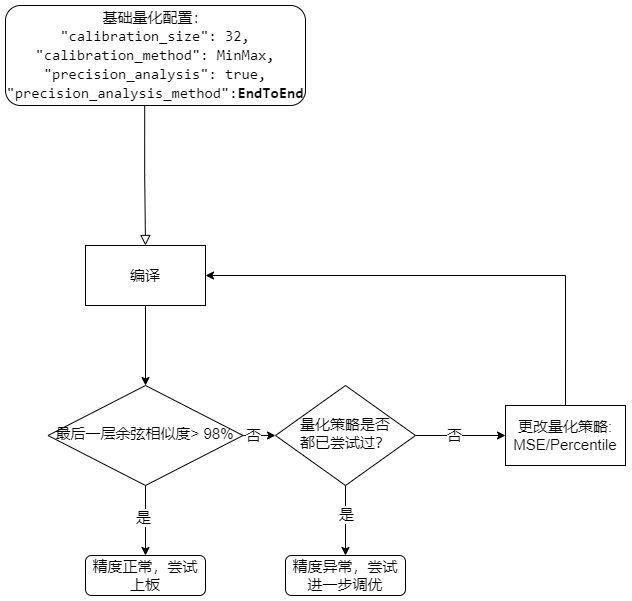
如果更改量化策略之后余弦相似度还是较低,可以根据 Quant Precision Table 【PerLayer Reference】 中余弦相似度来调节量化位宽,具体流程如下图所示。
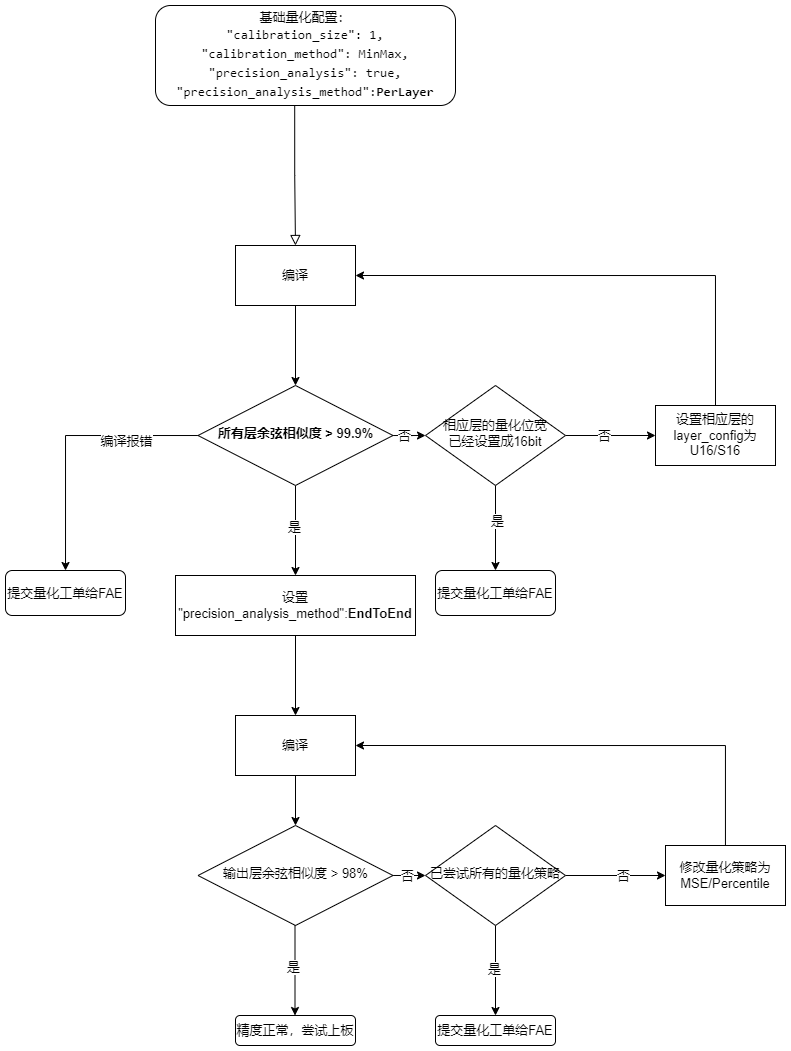
备注
需要注意的是,在编译阶段的量化精度分析工具的余弦相似度,并不等价于在测试数据集上的精度掉点情况(比如 AP , mAP )。
如果要掌握详细的数据集精度掉点情况,建议使用编译后的模型上板使用数据集测一遍模型精度。
6.3.3. 硬件精度实现差异#
配置文件中的选项 "precision_analysis_mode" 可选两个值:
"Reference" : 在进行逐层精度对比时,此时量化模型的推理引擎是参考实现,此时实际执行算子推理用的是
PyTorch / Numpy实现。"NPUBackend" : 在进行逐层精度对比时,此时量化模型的推理引擎是后端模拟实现,此时用的是相应的
NPU后端的仿真实现。
预期 "Reference" 与 "NPUBackend" 的结果是接近的,如果差异较大,则 NPU后端 仿真算子实现可能存在一定误差,此时建议将详细的log反馈给FAE。
6.4. 量化工单模板#
请详细填写以下项,并提交给 FAE/AE。
- 其他平台经验
是否有在其他平台部署过
对应厂商、芯片型号、相应工具链版本
其他平台的量化脚本或者配置文件
其他平台执行量化时的命令
相应的数据集指标:浮点精度 / 板上运行时精度 / 精度指标
- 提供可复现的最小case:
onnx 浮点模型
onnx 浮点模型的单张图片测试用例,python 或者 C++ 都行
config.json 配置文件
用于量化的最小数据集
Pulsar2 的编译命令
6.5. Q&A#
6.5.1. 怎么设置模型为全U16?#
{
"layer_configs": [
{
"start_tensor_names": ["DEFAULT"], # string of list
"end_tensor_names": ["DEFAULT"], # string of list
"data_type": "U16"
}
]
}
6.5.2. 为什么配置了 Add 算子量化位宽是 U16 在余弦相似度表里面看类型还是 U8?#
工具链会先将输入的浮点模型做一次浮点图优化再进行量化,这时配置的算子名/算子类型可能没有出现在浮点图优化后的模型
optimized.onnx里面,这时可以打开输出目录下的output/frontend/optimized.onnx查看该算子是否存在。量化后模型的输出可能与输入类型不同,就会经常出现余弦相似度表格里的算子输出类型与配置不同,这是因为下一个算子的输入类型可能并没有配置为相同位宽,这时会将算子的输出类型设置成下个算子的输入类型,以提升推理性能。这种优化并不会影响精度。
如果是
Reshape / Transpose等数据搬运类算子,设置该类算子的类型不会生效,它们的类型由下游的计算类算子类型决定。
6.5.3. outlier过大怎么办?#
模型中出现如下的日志,说明模型中激活值存在较多的 outlier ,我们建议使用 smooth quant 功能来降低这些 outlier。
Ratio of outliers in tensor【 level=Log(Max_Pertensor/Max_Perchannel) 】
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Op outputs ┃ Sparse channel ratio ┃ level>=3 ratio ┃ level>=4 ratio ┃ level>=5 ratio ┃ level>=6 ratio ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━┩
│ /vision_model/embeddings/patch_e… │ 0.0 │ 0.6614583134651184 │ 0.3111979067325592 │ 0.00390625 │ 0.0 │
├───────────────────────────────────┼──────────────────────┼────────────────────┼───────────────────────┼───────────────────────┼───────────────────────┤
│ op_348:onnx.LayerNormalization_0… │ 0.0 │ 0.921875 │ 0.5169270634651184 │ 0.1080729141831398 │ 0.0403645820915699 │
├───────────────────────────────────┼──────────────────────┼────────────────────┼───────────────────────┼───────────────────────┼───────────────────────┤
│ op_396:onnx.LayerNormalization_0… │ 0.0 │ 0.4427083432674408 │ 0.2473958283662796 │ 0.12109375 │ 0.0546875 │
├───────────────────────────────────┼──────────────────────┼────────────────────┼───────────────────────┼───────────────────────┼───────────────────────┤
│ op_821:onnx.AxFullyConnected_q_0… │ 0.0 │ 0.359375 │ 0.1875 │ 0.125 │ 0.0625 │
├───────────────────────────────────┼──────────────────────┼────────────────────┼───────────────────────┼───────────────────────┼───────────────────────┤
│ op_821:onnx.AxFullyConnected_k_0… │ 0.0 │ 0.203125 │ 0.078125 │ 0.0625 │ 0.015625 │
├───────────────────────────────────┼──────────────────────┼────────────────────┼───────────────────────┼───────────────────────┼───────────────────────┤
│ op_821:onnx.AxFullyConnected_v_0… │ 0.0 │ 0.453125 │ 0.203125 │ 0.078125 │ 0.03125 │
├───────────────────────────────────┼──────────────────────┼────────────────────┼───────────────────────┼───────────────────────┼───────────────────────┤
│ op_821:onnx.AxFullyConnected_q_1… │ 0.0 │ 0.234375 │ 0.125 │ 0.109375 │ 0.015625 │
├───────────────────────────────────┼──────────────────────┼────────────────────┼───────────────────────┼───────────────────────┼───────────────────────┤
│ op_821:onnx.AxFullyConnected_k_1… │ 0.0 │ 0.3125 │ 0.140625 │ 0.046875 │ 0.015625 │
├───────────────────────────────────┼──────────────────────┼────────────────────┼───────────────────────┼───────────────────────┼───────────────────────┤
│ op_821:onnx.AxFullyConnected_v_1… │ 0.0 │ 0.21875 │ 0.03125 │ 0.015625 │ 0.0 │
├───────────────────────────────────┼──────────────────────┼────────────────────┼───────────────────────┼───────────────────────┼───────────────────────┤
│ op_821:onnx.AxFullyConnected_q_2… │ 0.0 │ 0.296875 │ 0.203125 │ 0.140625 │ 0.09375 │
├───────────────────────────────────┼──────────────────────┼────────────────────┼───────────────────────┼───────────────────────┼───────────────────────┤
│ op_821:onnx.AxFullyConnected_k_2… │ 0.0 │ 0.234375 │ 0.109375 │ 0.0625 │ 0.015625 │
├───────────────────────────────────┼──────────────────────┼────────────────────┼───────────────────────┼───────────────────────┼───────────────────────┤
│ op_821:onnx.AxFullyConnected_v_2… │ 0.0 │ 0.234375 │ 0.125 │ 0.078125 │ 0.078125 │
├───────────────────────────────────┼──────────────────────┼────────────────────┼───────────────────────┼───────────────────────┼───────────────────────┤
│ op_821:onnx.AxFullyConnected_q_3… │ 0.0 │ 0.25 │ 0.09375 │ 0.078125 │ 0.03125 │
├───────────────────────────────────┼──────────────────────┼────────────────────┼───────────────────────┼───────────────────────┼───────────────────────┤
│ op_821:onnx.AxFullyConnected_k_3… │ 0.0 │ 0.1875 │ 0.109375 │ 0.03125 │ 0.015625 │
├───────────────────────────────────┼──────────────────────┼────────────────────┼───────────────────────┼───────────────────────┼───────────────────────┤
│ op_821:onnx.AxFullyConnected_v_3… │ 0.0 │ 0.296875 │ 0.15625 │ 0.0625 │ 0.0 │
├───────────────────────────────────┼──────────────────────┼────────────────────┼───────────────────────┼───────────────────────┼───────────────────────┤
│ op_821:onnx.AxFullyConnected_q_4… │ 0.0 │ 0.234375 │ 0.171875 │ 0.0625 │ 0.046875 │
├───────────────────────────────────┼──────────────────────┼────────────────────┼───────────────────────┼───────────────────────┼───────────────────────┤
│ op_821:onnx.AxFullyConnected_k_4… │ 0.0 │ 0.359375 │ 0.203125 │ 0.09375 │ 0.046875 │
通过配置 quant 字段中的 enable_smooth_quant 可以使能该功能。
提示
该方法来源于论文 SmoothQuant
6.5.4. csc mode 配置#
如果
csc_mode设置成除 YUYV422, UYVY422, YUV420SP, YVU420SP 时,上板时测试精度时预处理建议使用 IVE TDP做 resize ,该预处理与Opencv 的bilinear插值方式对齐。csc 转换并不包括
RGB2BGR和BGR2RGB,配置src_format为BGR或者BGR时在编译好的模型中实际是不做转换的。